- 40 Posts
- 291 Comments


 137·16 days ago
137·16 days agoOr just not show people what you’re typing.
That whole page is full of wild shit.

I can’t tell if this is a joke or not.
A computer like that is useful outside of work. I’d pay for it out of pocket if I had to.
 2·30 days ago
2·30 days agoYou keep moving the goal posts and putting words in my mouth. I never said you can do new things out of nothing. Nothing I mentioned is approaching, equaling, or exceeding the effort of training a model.
You haven’t answered a single one of my questions, and you are not arguing in good faith. We’re done here. I can’t say it’s been a pleasure.
Do you have any examples of how they fail? There are plenty of ways to explain new concepts to models.
https://arxiv.org/abs/2404.19427 https://arxiv.org/abs/2406.11643 https://arxiv.org/abs/2403.12962 https://arxiv.org/abs/2404.06425 https://arxiv.org/abs/2403.18922 https://arxiv.org/abs/2406.01300
What kind of creativity are you talking about then? I’ve also never heard of a bloated model. Which models are bloated?
But at what point does that guidance just become the dataset you removed from the training data?
The whole point is that it didn’t know the concepts beforehand, and no it doesn’t become the dataset. Observations made of the training data are added to the model’s weights after training, the dataset is never relevant again as the model’s weights are locked in.
To get it to run Doom, they used Doom.
To realize a new genre, you’ll “just” have to make that game the old fashion way, first.
Or you could train a more general model. These things happen in steps, research is a process.
There are more forms of guidance than just raw words. Just off the top of my head, there’s inpainting, outpainting, controlnets, prompt editing, and embeddings. The researchers who pulled this off definitely didn’t do it with text prompts.
I mean, you’ve never seen a purple elephant with a tennis racket. None of that exists in the data set since elephants are neither purple nor tennis players. Exposure to all the individual elements allows for generation of concepts outside the existing data, even though they don’t exit in reality or in the data set.
Is one of these cats just large or is this a trick of perspective?

The only thing I got from this is that bro loves ads more than anything in the world.
I accept regulations are real, but not all ways to help people require you dealing with regulations. I’m still waiting on that proof by the way.
There are more ways to help people than making medical software. Rather than saying they could focus on doing simpler things, you automatically jumping to all projects running afoul of FDA regulations is pretty telling. All while still having not provided a single project halted by FDA order.
Which projects have been shut down by FDA order?
Open source AI is huge, and I don’t think you need FDA approval to distribute a model. Where are you even getting that from?
What about open source projects?
 21·1 month ago
21·1 month agoI think it’s really disingenuous to mention the DeviantArt/Midjourney/Runway AI/Stability AI lawsuit without talking about how most of the infringement claims were dismissed by the judge.
This isn’t about research into AI, what some people want will impact all research, criticism, analysis, archiving. Please re-read the letter.










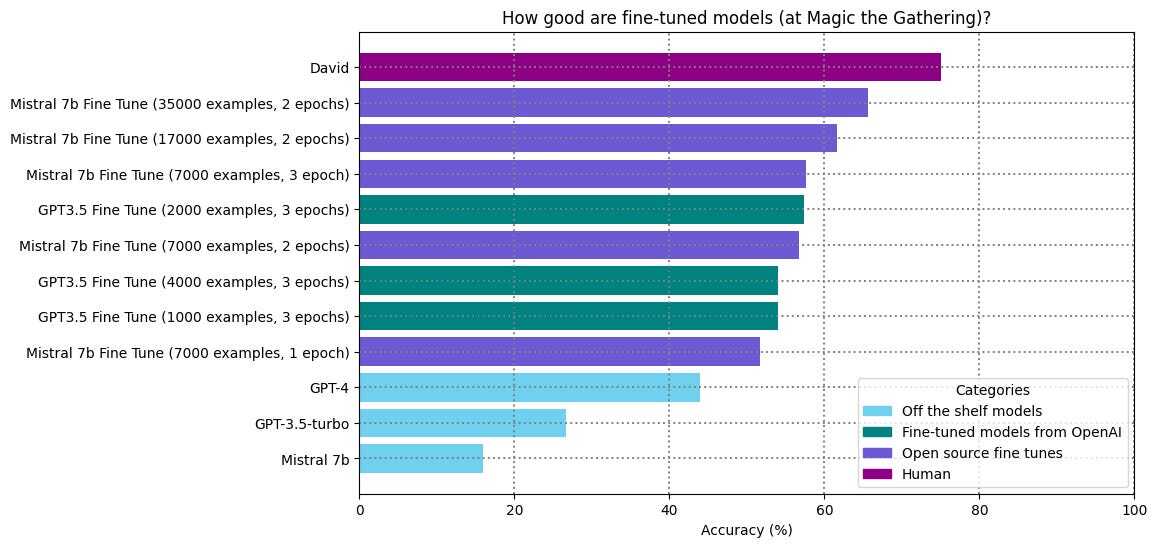




Is this an attempt to beat those monopoly allegations?